Human speech production and perception are bi-modal which involves evaluating the speaker’s visual cues and speech signal.
Audio-visual automatic speech recognition (AV-ASR) has been an active research area in today’s fastest growing world. This method uses both auditory and visual data to enhance speech recognition.
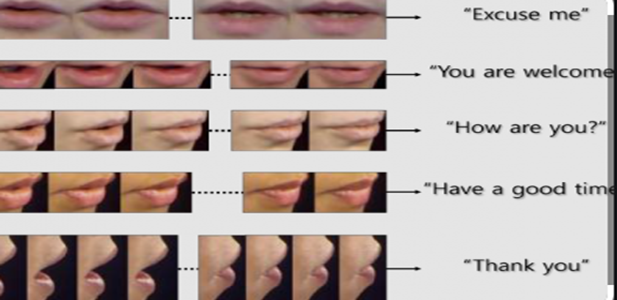
Why Audio-Visual Automatic Speech Recognition?
Speech is one of the most dominant ways and natural forms to express ourselves. The aim of Automatic Speech Recognition (ASR) is the translation of spoken words into text which means “what is being said” is correctly recognized by the system. Thus, to meet this human-machine interaction, noise-robust ASR is one of the blessings to the digital world. In real-time, the performance of the ASR system deteriorates in a public place where the background noise is very high. The real-world applications where ASR can be applied are in the authenticating system, voice dialing, data entry, dictation, translation, education, medical, military sector, and in many other applications. One of the most common application areas is Google voice search and interaction with android devices, where speech recognition is widely used. Thus, there is an exponential growth of ASR technology in many challenging real-life applications. In those applications, speech recognition gives a very good performance on a noise-free channel. But usually, the problem arises in a noisy environment, where ASR does not perform well. Many research has been done to reduce noise in speech signal and is successfully applied, however, the pattern and level of noise are required to know in advance. Lipreading is therefore an additional method for identifying speech in the midst of auditory noise. Human speech production is also a visual modality where one can understand the speech by seeing the speaker’s lip movement. Thus, the AV-ASR is a very reliable approach to support audio speech recognition, especially when the audio signal is corrupted in the presence of acoustic noise.
History of AV-ASR
In today’s fastest-growing digital world human-machine interfaces for intelligent devices such as smartphones, android systems, auto-driving cars, etc. are common in daily life. ASR has been an active research area for several decades. The aim of speech recognition is the translation of spoken words into text which means “what is being said” is correctly recognized by the system. Thus, to meet this human-machine interaction, noise-robust ASR is one of the blessings to the digital world. Many research has been done in the area of ASR over the past years. However, the accuracy of ASR greatly depends on the noise-free background. In real-time, the performance of the system deteriorates, when it is in a public space where the background noise is very high. Thus, the researchers have started working and found an additional source that gives satisfactory results in this domain. They have introduced visual information, which is extracted from the speaker’s mouth area to recognize speech. Visual clue is one of the reliable solutions used for recognition of visual speech when research in ASR reaches its highest goal. W. H Sumby and I. Pollack in 1954 first introduced the contribution of visual cues to speech intelligibility in noisy environments. The researchers have examined audio speech intelligibility tests and supplementary visual observation with the oral speech of the speaker’s facial and lip movements. The two conditions were analysed based on the speech-to-noise ratio factor and the size of the test vocabulary. N. P. Erber in 1975 also analyzed the auditory-visual perception of speech. The integration of audio and visual speech signals using machine learning has been developed in 1989. Since than AV-ASR has evolved a lot in the past years with various pioneering ideas by different researchers.
What are the benefits of AV-ASR for individual and large organizations?
Speech-based search or voice search is commonly used in smartphones and android devices. However, the user’s speech can be affected by background noise and as a result, they may not get the exact information they want. In those scenarios, AV-ASR can provide better results because of visual modality. Google voice search can use AV-ASR to improve searching technology.
For the security of many applications, devices, smartphones AV-ASR can be used. In today’s growing world, improved and secured customer services are the most significant tool for growth and development. Attackers use various algorithms to uncover secret information, pin-code for any social media application or to unlock any system. Therefore, secure authentication is a very important part of today’s digital world. Speech-based passwords can be used to secure any system but in a noisy environment, acoustic signals may not perform well. Thus, the combination of audio and visual modality improves system performance. AV-ASR can be used for remotes controlling of any electric home appliances. A smart home provides the control of lighting, climate, entertainment systems, and other appliances. AV-ASR can be used to control smart homes which also improves home security.
People with disabilities can utilise AV-ASR in a hands-free device for computing and searching.
AV-ASR improves the voice dialling performance in a noisy background. Speech-based documentation is very helpful in the health care sector to record a patient’s history, AV-ASR can help speech-based documentation in medical field. In those system, lip-reading with audio information can improve the performance of the system.
How it works?
Phases of AV-ASR: First step of developing AV-ASR is to collect audio video data. AV-ASR primarily consists of two phases: audio speech recognition and visual speech recognition. Both the audio and visual recognition is done by extracting audio and visual features. Another crucial step of AV-ASR is information fusion that combines both audio and visual recognition.
What are the common challenges in AV-ASR?
This study will help in hands-free computing in computer application, increase security in speech-based authentication, improve medical documentation, voice dialing, speech-based searching technique, etc. Despite being a relatively new area of work, there is still a challenge to extract proper visual articulations, because it is difficult to get proper visual articulations.
Therefore, researchers interested in AV-ASR are drawn to the extraction of correct visual articulation.
The research on AV-ASR based applications can be enhanced and extended to cover more scenarios with better results.
– Dr. Saswati Debnath
Assistant Professor, Computer Science and Engineering Department, ACED, Alliance University
– Dr. M Senbagavallli
Associate Professor, CST and IT Department, ACED, Alliance University